[생물통계학] 1.3 : next generation sequencing (NGS) - 1
이번 포스트부터는 NGS에 대해 알아보자.

대표적인 NGS 회사인 illumina와 MGI가 개발한 두 가지 종류의 platform을 예로 들어 살펴보자.
Illumina sequencing
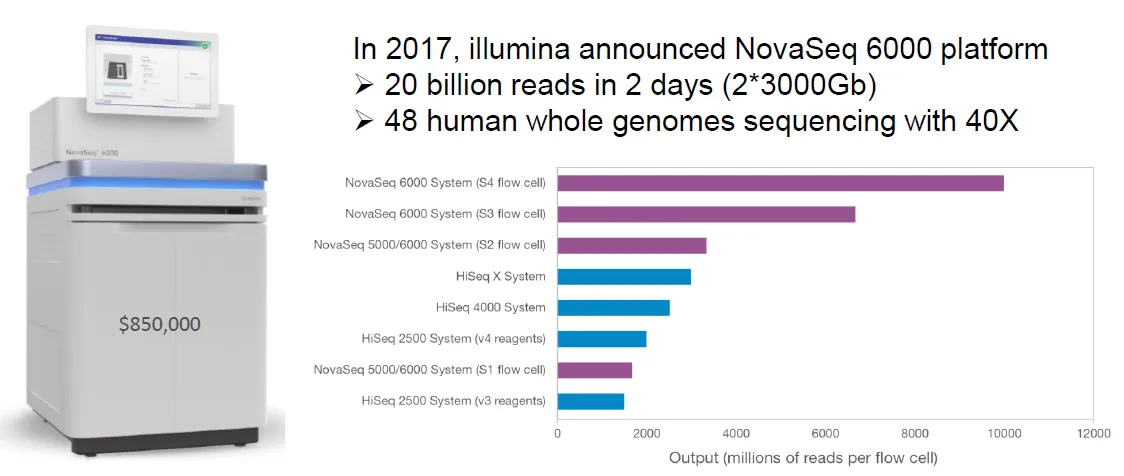
위 그림에는 Illumina가 개발한 각종 genome sequencing 장비들이 비교되어 나타나 있음. 보면 구체적인 작동 방식에 따라, 같은 방식으로 sequencing을 수행함에도 읽어낼 수 있는 read의 수가 달라짐을 알 수 있음.
이 중 2017년에 개발된 NovaSeq 6000이 가장 최신의 platform이며 이 녀석을 이용할 시 2일만에 20 billion read를 얻어낼 수 있고 이는 48명분의 whole genome을 40X coverage로 sequencing하는 것과 identical함.

구체적으로 Illumina sequencing 장비의 경우 위 그림상에 묘사된 reversible dye-terminator를 이용해서 sequencing을 수행함.
이 장비 또한 기본적인 principle은 sequencing-by-synthesis(SBS)이며, 다만 이 경우 한 step에서 첨가되는 nucleotide의 끝에 reversible terminator가 결합해있어서 한 step에서는 하나의 반응만 일어날 수 있고, 이후 이 terminator moiety를 cleave한 다음에 다음 step의 반응을 지속시켜줄 수 있으므로 하나하나의 base를 sequencing할 수 있게 되는 것임. (이 때 각각의 첨가되는 nucleotide는 저마다의 fluorescence를 낼 수 있기 때문에 이를 detection할 시 sequencing이 가능한 것임)
그런데 여기서 문제가 있음. 위와 같은 방식으로 fluorescence를 detection해서 sequencing을 할 경우 optical detector가 형광을 인식하기에는 한 nucleotide로부터 나오는 형광이 너무 약하다는 것임.


이 문제를 해결하기 위해 Illumina에서는 위와 같이 bridge amplification step을 통해 동일한 sequence를 무수히 많이 clustering시킨 후 한 cluster 전체에서 signal을 읽어냄.

구체적으로는 위와 같이 생긴 FLowcell에 adaptor에 해당하는 서열들을 immobilize시켜둔 후 이미 양 가쪽에 adaptor가 부착되어 있는 DNA를 이곳에 뿌린 뒤에 앞서의 그림에서 묘사된것과 같이 bridge amplification step을 거쳐서 1000개 이상의 identical한 copy를 생성하게 됨.

위 그림에는 실제로 Flowcell에 결합한 채 bridge amplification된 결과 얻어진 cluster가 나타나 있으므로 참고할 것. 보면 이 경우 생성되는 cluster의 위치가 random하다는 것이 특징적임. 이렇게 random한데에는 이유가 있는데, chemical한 method로 Flowcell 바닥에 incorporation시킬 때 even하지 않게 깔리는 경우가 많기 때문임. 이 때문에 때때로 Flowcell 자체의 quality가 낮아서 sequencing quality 또한 낮아지는 현상이 발생할 수 있음.
그 밖에도, ideal한 상황과는 달리, 실제로는 template의 synchronization loss가 분명히 발생하며, 특별히 몇몇 sequence들의 incomplete한 terminator removal 등이 일어나거나 혹은 cycle이 missing되거나, 또한 하나, 혹은 몇개의 base가 더 추가된 상태로(pre-phasing) sequencing이 진행될 수 있으므로 sync가 맞지 않을 수 있음.

위 그림은 합성되는 base pair 길이에 따른 quality score를 보여주고 있음. 이 때 quality score가 높을수록 error rate가 더 적음을 의미함. (즉, quality score가 높을수록 더 정확한 sequencing이 이루어지고 있는 것임) 보면 초반에는 sequencing을 시작하면서의 efficiency 차이 등으로 인해 sync가 맞지 않아 잠시 quality score가 낮고, 이후 특정 기간동안 쭉 quality score가 높다가 다시금 뒤로갈수록 서서히 pre-phasing에 의해서 quality score가 낮아짐을 알 수 있음.
따라서 sequencing 결과를 받았을 때 우리가 원하는 긴 길이까지도 quality score가 낮아지지 않고 계속 유지된다면 sequencing이 잘 이루어졌다고 판단하면 되며 만약 위와 같이 서서히 decrease하는 형태의 quality score가 얻어졌다면 sequencing이 잘 이루어지지 않았다고 판단하면 됨.
다음 포스트에서 이어서 살펴보자.